markusk2510
Neuer Benutzer
- Beiträge
- 3
Hallo,
gleich zu Anfang mal ein Dankeschön an all jene die die etwas lange Problem-Beschreibung bis zum Ende lesen und ggf. antworten.
Ich soll da für ein mittelständiges Unternehmen eine Verkäuferstatistik erstellen.
Als Datenbasis hab ich eine CSV-Datei mit den benötigten Daten (mehre hunderttausend Zeilen und täglich steigend) zur Verfügung.
Jede Zeile hat eine Spalte mit einem Erfassungskennzeichen (Spalte ErfKz)
R=Rechnungsposition
S=Stornoposition
L=Lieferscheinposition
z.B.
ErfKz;Datum;KundNr;Vertreter;Menge;VorgangsNr;Verk.Wert;Einst.Wert
R;20180102;901744;133;1,0000;180002;470,00;237,98
S;20180110;510542;731;1,0000-;780036;31,50-;20,91-
L;20150206;892929;130;2,0000;150190;0,00;13,46
Die Stornopositionen erkennt man außer dem Erfassungskennzeichen "S" an der negativen Menge und den negativen Beträgen.
Der erste Schritt war der Import dieser Daten in die Datenbank.
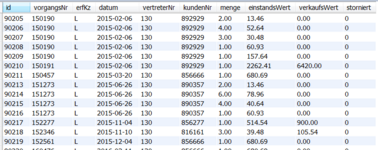
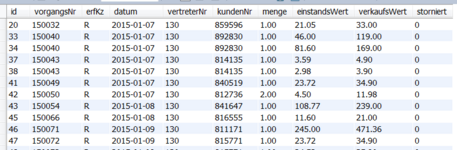
Um die zu analysierende Datenmenge pro Vertreter zu verringern hab ich die R-Zeilen, die S-Zeilen und die L-Zeilen pro Vertreter jeweils in eigene Tabellen geschrieben. Jeder Vertreter hat also seine eigenen drei Tabellen wobei die Zahl hinten beim Tabellennamen nicht die Vertreternummer aus der CSV-Datei darstellt sondern seine Id in der Vertretertabelle.
rzeilen_v1
szeilen_v1
lzeilen_v1
rzeilen_v2
szeilen_v2
lzeilen_v2
.
.
.
usw.
Ansicht dieser Tabellen liegen bei.
Durch diese Aufteilung kann ich die Datenmenge auf denen die SELECTS und UPDATES operieren gewaltig reduzieren da die Tabellen ja nur die Daten eines bestimmten Vertreters enthalten. Die Daten der anderen Vertreter sind ja für die Umsatzanalyse eines bestimmten Vertreters irrelevant.
Und es macht sicher einen Unterschied ob ein Statement auf 500.000 oder auf 50.000 Datensätzen ausgeführt wird.
Leider waren vor der Umsatzberechnung noch einige Vorarbeiten nötig da die Daten ein paar Besonderheiten aufweisen, z.B. bei der VorgangsNr
Rechnungspositionen und Lieferscheinpositionen verwenden für die Vorgangsnummer denselben Nummernkreis, d.h. es kann eine Rechnungsposition mit der VorgangsNr 12345 und eine Lieferscheinposition mit der VorgangsNr 12345 geben. Dadurch kann man bei den Stornopositionen nicht eindeutig erkennen ob da nun eine Rechnungsposition oder eine Lieferscheinposition storniert wird da in der Stornozeile ja nur die Vorgangsnummer enthalten ist.
Ich musste daher durch Vergleichen der Felder VorgangsNr, VertreterNr, Menge und Verkaufswert für jede S-Zeile herausfinden ob es sich dabei um das Storno einer Rechnungsposition oder um das Storno einer Lieferscheinposition handelt.
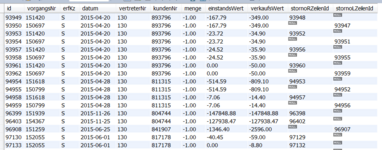
Um die S-Zeile entsprechend zu markieren hab ich die Tabelle um zwei Spalten erweitert (stornoRZeilenId und stornoLZeilenId)
Nun gehe ich die S-Zeilen der Reihe nach durch und schaue in den R-Zeilen nach ob es einen Eintrag gibt der in VorgangsNr, VertreterNr, Menge und Verkaufswert übereinstimmt. Wenn es einen gibt wird dessen Id in der Spalte stornoRZeilenId vermerkt.
Dasselbe mach ich mit den L-Zeilen und speichere deren Ids in der Spalte stornoLZeilenId.
Nun kann ich erkennen ob eine S-Zeile zu einer R-Zeile gehört oder zu einer L-Zeile.
Entweder ist stornoRZeilenId befüllt oder stornoLZeilenId.
Wenn beide befüllt wurden dann passt das Storno basierend auf den Vergleichskriterien sowohl zu einer R-Zeile als auch zu einer L-Zeile.
Falls keines der beiden Felder befüllt wurde dann gibt es zu diesem Storno keine passende R- oder L-Zeile.
Beide Fälle müssen dann vom Kunden näher untersucht werden.
Ich hab die Befüllung der beiden Spalten mit folgenden Statements durchgeführt (hier die Statements für den Verkäufer 1):
Abgleich mit den R-Zeilen:
update szeilen_v1 szv
join rzeilen_v1 rzv on
szv.vorgangsnr=rzv.vorgangsnr and
szv.vertreternr=rzv.vertreternr and
szv.menge=-rzv.menge and
(szv.verkaufswert=-rzv.verkaufswert or (szv.verkaufswert=0 and rzv.verkaufswert=0))
set stornoRZeilenId=rzv.id where stornoRZeilenId is null and szv.id > 0;
Abgleich mit den S-Zeilen:
update szeilen_v1 szv
join lzeilen_v1 lzv on
szv.vorgangsnr=lzv.vorgangsnr and
szv.vertreternr=lzv.vertreternr and
szv.menge=-lzv.menge and
(szv.verkaufswert=-lzv.verkaufswert or (szv.verkaufswert=0 and lzv.verkaufswert=0))
set stornoLZeilenId=lzv.id where stornoLZeilenId is null and szv.id > 0;
Machen diese Statements das was ich gerade beschrieben habe?
lg, Markus
gleich zu Anfang mal ein Dankeschön an all jene die die etwas lange Problem-Beschreibung bis zum Ende lesen und ggf. antworten.
Ich soll da für ein mittelständiges Unternehmen eine Verkäuferstatistik erstellen.
Als Datenbasis hab ich eine CSV-Datei mit den benötigten Daten (mehre hunderttausend Zeilen und täglich steigend) zur Verfügung.
Jede Zeile hat eine Spalte mit einem Erfassungskennzeichen (Spalte ErfKz)
R=Rechnungsposition
S=Stornoposition
L=Lieferscheinposition
z.B.
ErfKz;Datum;KundNr;Vertreter;Menge;VorgangsNr;Verk.Wert;Einst.Wert
R;20180102;901744;133;1,0000;180002;470,00;237,98
S;20180110;510542;731;1,0000-;780036;31,50-;20,91-
L;20150206;892929;130;2,0000;150190;0,00;13,46
Die Stornopositionen erkennt man außer dem Erfassungskennzeichen "S" an der negativen Menge und den negativen Beträgen.
Der erste Schritt war der Import dieser Daten in die Datenbank.
Um die zu analysierende Datenmenge pro Vertreter zu verringern hab ich die R-Zeilen, die S-Zeilen und die L-Zeilen pro Vertreter jeweils in eigene Tabellen geschrieben. Jeder Vertreter hat also seine eigenen drei Tabellen wobei die Zahl hinten beim Tabellennamen nicht die Vertreternummer aus der CSV-Datei darstellt sondern seine Id in der Vertretertabelle.
rzeilen_v1
szeilen_v1
lzeilen_v1
rzeilen_v2
szeilen_v2
lzeilen_v2
.
.
.
usw.
Ansicht dieser Tabellen liegen bei.
Durch diese Aufteilung kann ich die Datenmenge auf denen die SELECTS und UPDATES operieren gewaltig reduzieren da die Tabellen ja nur die Daten eines bestimmten Vertreters enthalten. Die Daten der anderen Vertreter sind ja für die Umsatzanalyse eines bestimmten Vertreters irrelevant.
Und es macht sicher einen Unterschied ob ein Statement auf 500.000 oder auf 50.000 Datensätzen ausgeführt wird.
Leider waren vor der Umsatzberechnung noch einige Vorarbeiten nötig da die Daten ein paar Besonderheiten aufweisen, z.B. bei der VorgangsNr
Rechnungspositionen und Lieferscheinpositionen verwenden für die Vorgangsnummer denselben Nummernkreis, d.h. es kann eine Rechnungsposition mit der VorgangsNr 12345 und eine Lieferscheinposition mit der VorgangsNr 12345 geben. Dadurch kann man bei den Stornopositionen nicht eindeutig erkennen ob da nun eine Rechnungsposition oder eine Lieferscheinposition storniert wird da in der Stornozeile ja nur die Vorgangsnummer enthalten ist.
Ich musste daher durch Vergleichen der Felder VorgangsNr, VertreterNr, Menge und Verkaufswert für jede S-Zeile herausfinden ob es sich dabei um das Storno einer Rechnungsposition oder um das Storno einer Lieferscheinposition handelt.
Um die S-Zeile entsprechend zu markieren hab ich die Tabelle um zwei Spalten erweitert (stornoRZeilenId und stornoLZeilenId)
Nun gehe ich die S-Zeilen der Reihe nach durch und schaue in den R-Zeilen nach ob es einen Eintrag gibt der in VorgangsNr, VertreterNr, Menge und Verkaufswert übereinstimmt. Wenn es einen gibt wird dessen Id in der Spalte stornoRZeilenId vermerkt.
Dasselbe mach ich mit den L-Zeilen und speichere deren Ids in der Spalte stornoLZeilenId.
Nun kann ich erkennen ob eine S-Zeile zu einer R-Zeile gehört oder zu einer L-Zeile.
Entweder ist stornoRZeilenId befüllt oder stornoLZeilenId.
Wenn beide befüllt wurden dann passt das Storno basierend auf den Vergleichskriterien sowohl zu einer R-Zeile als auch zu einer L-Zeile.
Falls keines der beiden Felder befüllt wurde dann gibt es zu diesem Storno keine passende R- oder L-Zeile.
Beide Fälle müssen dann vom Kunden näher untersucht werden.
Ich hab die Befüllung der beiden Spalten mit folgenden Statements durchgeführt (hier die Statements für den Verkäufer 1):
Abgleich mit den R-Zeilen:
update szeilen_v1 szv
join rzeilen_v1 rzv on
szv.vorgangsnr=rzv.vorgangsnr and
szv.vertreternr=rzv.vertreternr and
szv.menge=-rzv.menge and
(szv.verkaufswert=-rzv.verkaufswert or (szv.verkaufswert=0 and rzv.verkaufswert=0))
set stornoRZeilenId=rzv.id where stornoRZeilenId is null and szv.id > 0;
Abgleich mit den S-Zeilen:
update szeilen_v1 szv
join lzeilen_v1 lzv on
szv.vorgangsnr=lzv.vorgangsnr and
szv.vertreternr=lzv.vertreternr and
szv.menge=-lzv.menge and
(szv.verkaufswert=-lzv.verkaufswert or (szv.verkaufswert=0 and lzv.verkaufswert=0))
set stornoLZeilenId=lzv.id where stornoLZeilenId is null and szv.id > 0;
Machen diese Statements das was ich gerade beschrieben habe?
lg, Markus