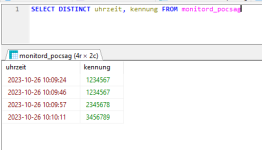
Hallo,
wie kann ich doppelte Einträge ausblenden, wenn zwei Werte gleich sind?
Wenn der Wert "Kennung" doppelt ist + der Wert "Uhrzeit" doppelt ist als Bedingung.
DISTINCT wert1 and wert2
SELECT * FROM monitord_pocsag
JOIN monitord_bezeichnung
WHERE LEFT (monitord_pocsag.kennung, 7) = LEFT(monitord_bezeichnung.kennung, 7)
DISTINCT (monitord_pocsag.uhrzeit) AND (monitord_pocsag.kennung)
ORDER BY monitord_pocsag.id
wie kann ich doppelte Einträge ausblenden, wenn zwei Werte gleich sind?
Wenn der Wert "Kennung" doppelt ist + der Wert "Uhrzeit" doppelt ist als Bedingung.
DISTINCT wert1 and wert2
SELECT * FROM monitord_pocsag
JOIN monitord_bezeichnung
WHERE LEFT (monitord_pocsag.kennung, 7) = LEFT(monitord_bezeichnung.kennung, 7)
DISTINCT (monitord_pocsag.uhrzeit) AND (monitord_pocsag.kennung)
ORDER BY monitord_pocsag.id