Aljoscha.Peters
Neuer Benutzer
- Beiträge
- 3
Hi Leute,
ich arbeite gerade an meiner Abschlussarbeit. Diese basiert u.a. auf einer MySQL-Datenbank. Diese ist ordentlich normalisiert. Nun brauche ich eine Tabelle, die von mehreren Tabellen befüllt wird. Woran es scheitert, sind die JOINS. Da setzt mein Kopf gerade aus und deshalb baue ich auf Eure Hilfe. O")
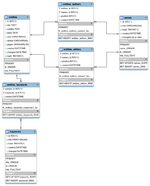
Ich habe 5 Tabellen: entities, keywords, names, entities_keywords, entities_authors; die sind wie folgt aufgebaut:
entities: id : int, title : text, ..., trash : tinyint
keywords: id : int, title : text, trash : tinyint
names: id : int, title : text, trash : tinyint
entities_keywords: entities_id : int, keywords_id : int (zusammengesetzter primary index aus entities_id und keywords_id)
entities_authors: entities_id : int, names_id : int, position : int
Die normalen Verknüpfungen (n-m-Relation) zur Anzeige funktionieren wunderbar. Updaten/Löschen ... alles super.
Jetzt brauche ich für die Realisierung der Suche folgendes:
Ich habe eine neue Tabelle erstellt (search_entities_authors_keywords), die erst einmal - um es zu vestehen - befüllt werden soll mit den Daten der m-n-Relationen von oben. Bisher bin nur erfolgreich bei Tabellen wie bspw. (search_entities_keywords), die dann folgendes machen:
INSERT `search_entities_keywords` (`id`, `title`, `year`,`keywords`
SELECT `e`.`id`, `e`.`title`,`e`.`year`, GROUP_CONCAT(`k`.`title` ORDER BY `k`.`title` SEPARATOR ',')
FROM
((`entities_keywords`
LEFT JOIN `keywords` `k` ON ((`entities_keywords`.`keywords_id` = `k`.`id`)))
LEFT JOIN `entities` `e` ON ((`entities_keywords`.`entities_id` = `e`.`id`)))
WHERE `e`.`trash` = 0 AND `k`.`trash` = 0
GROUP BY `slipbox`.`entities_keywords`.`entities_id`
ORDER BY `e`.`title` ASC
Mir ist also unklar, wie ich es anstellen muss, dass ich ALLE entities bekomme (mit e.trash=0), mit allen Keywords und Authors!
Ich muss ja eigentlich dann SELECT ... FROM entities nutzen mit mehreren JOINS über die Verknüpfungstabellen entities_keywords und entities_authors. Aber wie ich das mache, ist mir total schleierhaft!
Ich danke Euch im Voraus schon einmal gaaaaanz herzlich und wünsche weiterhin ein schönes Wochenende.
Aljoscha
ich arbeite gerade an meiner Abschlussarbeit. Diese basiert u.a. auf einer MySQL-Datenbank. Diese ist ordentlich normalisiert. Nun brauche ich eine Tabelle, die von mehreren Tabellen befüllt wird. Woran es scheitert, sind die JOINS. Da setzt mein Kopf gerade aus und deshalb baue ich auf Eure Hilfe. O
Ich habe 5 Tabellen: entities, keywords, names, entities_keywords, entities_authors; die sind wie folgt aufgebaut:
entities: id : int, title : text, ..., trash : tinyint
keywords: id : int, title : text, trash : tinyint
names: id : int, title : text, trash : tinyint
entities_keywords: entities_id : int, keywords_id : int (zusammengesetzter primary index aus entities_id und keywords_id)
entities_authors: entities_id : int, names_id : int, position : int
Die normalen Verknüpfungen (n-m-Relation) zur Anzeige funktionieren wunderbar. Updaten/Löschen ... alles super.
Jetzt brauche ich für die Realisierung der Suche folgendes:
Ich habe eine neue Tabelle erstellt (search_entities_authors_keywords), die erst einmal - um es zu vestehen - befüllt werden soll mit den Daten der m-n-Relationen von oben. Bisher bin nur erfolgreich bei Tabellen wie bspw. (search_entities_keywords), die dann folgendes machen:
INSERT `search_entities_keywords` (`id`, `title`, `year`,`keywords`
SELECT `e`.`id`, `e`.`title`,`e`.`year`, GROUP_CONCAT(`k`.`title` ORDER BY `k`.`title` SEPARATOR ',')
FROM
((`entities_keywords`
LEFT JOIN `keywords` `k` ON ((`entities_keywords`.`keywords_id` = `k`.`id`)))
LEFT JOIN `entities` `e` ON ((`entities_keywords`.`entities_id` = `e`.`id`)))
WHERE `e`.`trash` = 0 AND `k`.`trash` = 0
GROUP BY `slipbox`.`entities_keywords`.`entities_id`
ORDER BY `e`.`title` ASC
Mir ist also unklar, wie ich es anstellen muss, dass ich ALLE entities bekomme (mit e.trash=0), mit allen Keywords und Authors!
Ich muss ja eigentlich dann SELECT ... FROM entities nutzen mit mehreren JOINS über die Verknüpfungstabellen entities_keywords und entities_authors. Aber wie ich das mache, ist mir total schleierhaft!
Ich danke Euch im Voraus schon einmal gaaaaanz herzlich und wünsche weiterhin ein schönes Wochenende.
Aljoscha