Hi,
ich habe hier eine PZE ähnliche Software. Hier wird täglich ein wert für den Start und ein Wert für das Ende weggeschrieben.
Beispiel
Derselbe Mitarbeiter hat also an 2 Tagen Jeweils Start (Status 1 und Ende Status 2) bemeldet.
Nun möchte ich über einen Monat oder eine KW oder wie auch immer (Datepart komme ich mit zurecht) Die Differenz zwischen Status 1 und 2 errechnen und für den gewählten Zeitraum summieren. Hier wären das also an 2 Tagen insgesamt 20 Stunden. Als Newbie in SQL stellt man sich manchmal echt an wie der erste Mensch.... Ich hoffe mal wieder auf eine nette Person die mir hilft")
Danke schonmal im Voraus.
ich habe hier eine PZE ähnliche Software. Hier wird täglich ein wert für den Start und ein Wert für das Ende weggeschrieben.
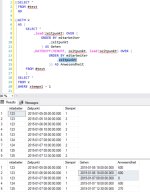
Beispiel
| Mitarbeiter | Zeitpunkt | Status | |
| 123 | 2015-01-05 08:00:00.000 | 1 | |
| 123 | 2015-01-05 18:00:00.000 | 2 | |
| 123 | 2015-01-06 08:00:00.000 | 1 | |
| 123 | 2015-01-06 18:00:00.000 | 2 |
Derselbe Mitarbeiter hat also an 2 Tagen Jeweils Start (Status 1 und Ende Status 2) bemeldet.
Nun möchte ich über einen Monat oder eine KW oder wie auch immer (Datepart komme ich mit zurecht) Die Differenz zwischen Status 1 und 2 errechnen und für den gewählten Zeitraum summieren. Hier wären das also an 2 Tagen insgesamt 20 Stunden. Als Newbie in SQL stellt man sich manchmal echt an wie der erste Mensch.... Ich hoffe mal wieder auf eine nette Person die mir hilft
Danke schonmal im Voraus.