ramboni
Benutzer
- Beiträge
- 17
Hallo zusammen,
SQL ist für mich noch sehr neu aber ich hoffe ihr könnt mir helfen.
Meine Datenbank sieht so aus: (m =männlich, w = weiblich)
Vorname, Geschlecht
Tom,m
Ilse,w
Eike,m
Eike,w
Ich habe ca 2000 Unisex Namen in der Datenbank, ich wollte anfangen alle per Hand auf 'u' zu ändern,
ich habe aufgegeben und suche nun eine Lösung per SQL.
Was soll passieren?
Wenn ich nur genau einen Treffer habe soll das Geschlecht ausgegeben werden.
Wenn es mehr als ein Treffer gibt, soll ein 'u' für unisex ausgegeben werden.
Was hab ich versucht? So ziemlich alles
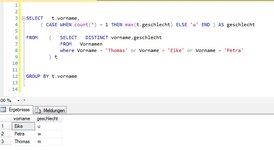
Das hier klingt in meiner Welt logisch, ist es für SQL anscheinend nicht.
select case when count(Vorname) > 1 then 'u'
else Geschlecht
end
from Vornamen
where Vorname = 'Eike'
Könnt ihr mir helfen?
SQL ist für mich noch sehr neu aber ich hoffe ihr könnt mir helfen.
Meine Datenbank sieht so aus: (m =männlich, w = weiblich)
Vorname, Geschlecht
Tom,m
Ilse,w
Eike,m
Eike,w
Ich habe ca 2000 Unisex Namen in der Datenbank, ich wollte anfangen alle per Hand auf 'u' zu ändern,
ich habe aufgegeben und suche nun eine Lösung per SQL.
Was soll passieren?
Wenn ich nur genau einen Treffer habe soll das Geschlecht ausgegeben werden.
Wenn es mehr als ein Treffer gibt, soll ein 'u' für unisex ausgegeben werden.
Was hab ich versucht? So ziemlich alles
Das hier klingt in meiner Welt logisch, ist es für SQL anscheinend nicht.
select case when count(Vorname) > 1 then 'u'
else Geschlecht
end
from Vornamen
where Vorname = 'Eike'
Könnt ihr mir helfen?
") Da werd ich noch viel üben müssen.
Da werd ich noch viel üben müssen.